Leveldb 源码详解系列之四: 迭代器设计与实现
主要内容:
1 迭代器接口设计
1.1 迭代器实现一例
2 双层迭代器设计
迭代器的设计和实现是 leveldb 的精华之一. 前几篇文章都多少提到了迭代器的使用, 本篇让我们深入一下迭代器的设计实现, 也为接下来的几篇剖析打下基础.
1 迭代器接口设计
迭代器接口类为 leveldb::Iterator, 位于 include/leveldb/iterator.h 和 table/iterator.cc. (实现位于 table 目录, 是因为接下来要介绍的 sstable 是迭代器重度用户.)
迭代器接口定义比较简洁, 主要方法为指向合法性判断, 前后移动, 定位(开头/末尾/任意), 提取数据项 key/value 等等.
唯一的数据成员为清理函数列表头节点.
具体如下:
class LEVELDB_EXPORT Iterator {
public:
Iterator();
// 禁用复制构造
Iterator(const Iterator&) = delete;
// 禁用赋值构造
Iterator& operator=(const Iterator&) = delete;
virtual ~Iterator();
// 一个迭代器要么指向 key/value 对, 要么指向非法位置.
// 当且仅当第一种情况才为 valid.
virtual bool Valid() const = 0;
// 将迭代器移动到数据源的第一个 key/value 对.
// 当前仅当数据源不空时, 调用完该方法再调用 Valid() 为 true.
virtual void SeekToFirst() = 0;
// 将迭代器移动到数据源的最后一个 key/value 对.
// 当前仅当数据源不空时, 调用完该方法再调用 Valid() 为 true.
virtual void SeekToLast() = 0;
// 将迭代器指向移动到数据源 target 位置或之后的第一个 key.
// 当且仅当移动后的位置存在数据项时, 调用 Valid() 才为 true.
virtual void Seek(const Slice& target) = 0;
// 将迭代器移动到数据源下一个数据项.
// 当且仅当迭代器未指向数据源最后一个数据项时, 调用完该方法后调用 Valid() 结果为 true.
// 注意: 调用该方法前提是迭代器当前指向必须 valid.
virtual void Next() = 0;
// 将迭代器移动到数据源前一个数据项.
// 当且仅当迭代器未指向数据源第一个数据项时, 调用完该方法后调用 Valid() 结果为 true.
// 注意: 调用该方法前提是迭代器当前指向必须 valid.
virtual void Prev() = 0;
// 返回当前迭代器指向的数据项的 key, Slice 类型, 如果使用迭代器进行修改则会反映到
// 已返回的 key 上面.
// 注意: 调用该方法前提是迭代器当前执行必须 valid.
virtual Slice key() const = 0;
// 返回当前迭代器指向的数据项的 value, Slice 类型, 如果使用迭代器进行修改则会反映到
// 已返回的 value 上面.
// 注意: 调用该方法前提是迭代器当前执行必须 valid.
virtual Slice value() const = 0;
// 发生错误返回之; 否则返回 ok.
virtual Status status() const = 0;
// 我们允许调用方注册一个带两个参数的回调函数, 当迭代器析构时该函数会被自动调用.
using CleanupFunction = void (*)(void* arg1, void* arg2);
// 我们允许客户端注册 CleanupFunction 类型的回调函数, 在迭代器被销毁的时候会调用它们(可以注册多个).
// 注意, 跟前面的方法不同, RegisterCleanup 不是抽象的, 客户端不应该覆写他们.
void RegisterCleanup(CleanupFunction function, void* arg1, void* arg2);
private:
// 清理函数被维护在一个单向链表上, 其中头节点被 inlined 到迭代器中.
// 该类用于保存用户注册的清理函数, 一个清理函数对应一个该类对象, 全部对象被维护在一个单向链表上.
struct CleanupNode {
// 清理函数及其两个参数
CleanupFunction function;
void* arg1;
void* arg2;
// 下个清理函数
CleanupNode* next;
// 判断清理函数是否为空指针.
bool IsEmpty() const { return function == nullptr; }
// 运行调用方通过 Iterator::RegisterCleanup 注册的清理函数
void Run() { assert(function != nullptr); (*function)(arg1, arg2); }
};
// 清理函数列表的头节点
CleanupNode cleanup_head_;
}Iterator 本身实现了三个方法, 分别是构造方法, 析构方法, 以及清理函数注册方法. 下面是非抽象方法的实现:
// 构造方法, 初始化唯一数据成员
Iterator::Iterator() {
cleanup_head_.function = nullptr;
cleanup_head_.next = nullptr;
}
Iterator::~Iterator() {
// 析构时调用已注册的清理函数
if (!cleanup_head_.IsEmpty()) {
// 线性的, 如果在该迭代器上注册的清理函数太多了应该会影响性能, 但总要做释放操作, 时间总归省不了.
cleanup_head_.Run();
for (CleanupNode* node = cleanup_head_.next; node != nullptr; ) {
node->Run();
CleanupNode* next_node = node->next;
delete node;
node = next_node;
}
}
}
// 将用户定制的清理函数挂到单向链表上, 待迭代器销毁时挨个调用(见 ~Iterator()).
void Iterator::RegisterCleanup(CleanupFunction func, void* arg1, void* arg2) {
assert(func != nullptr);
CleanupNode* node;
if (cleanup_head_.IsEmpty()) {
node = &cleanup_head_;
} else {
node = new CleanupNode();
// 新节点插到 head 后面
node->next = cleanup_head_.next;
cleanup_head_.next = node;
}
node->function = func;
node->arg1 = arg1;
node->arg2 = arg2;
}1.1 迭代器实现一例
下面以 sstable 的 block 为例示意一下迭代器的实现. 关键部分就是将 block 作为迭代器数据源, 基于 block 构造和查询原理实现迭代器的前后移动, 定位等操作. 里面涉及了一些成员看不懂也不用管, 在介绍 sstable 时会解释.
具体类为 leveldb::Block::Iter, 代码位于 table/block.cc 文件:
class Block::Iter : public Iterator {
private:
// 迭代时使用的比较器
const Comparator* const comparator_;
// 指向 block 的指针
const char* const data_;
// block 的 restart 数组
// (每个元素 32 位固定长度, 保存着每个 restart 在 block 里的偏移量)
// 在 block 里的起始偏移量
uint32_t const restarts_;
// restart 数组元素个数(每个元素都是 uint32_t 类型)
uint32_t const num_restarts_;
// current_ 表示当前数据项在 data_ 里的偏移量,
// 如果迭代器无效则该值大于等于 restarts_
// 即 restart array 在 block 的起始偏移量
// (restart array 位于 block 后部, 数据项在 block 前半部分)
uint32_t current_;
// restart block 的索引值, current_ 指向的数据项落在该 block
uint32_t restart_index_;
// current_ 所指数据项的 key
std::string key_;
// current_ 所指数据项的 value
Slice value_;
// 当前迭代器对应的状态
Status status_;
inline int Compare(const Slice& a, const Slice& b) const {
return comparator_->Compare(a, b);
}
// 返回 current_ 所指数据项的下一个数据项的偏移量.
// 根据 Block 布局我们可以知道, value 位于每个数据项最后,
// 所以 value 之后第一个字节即为下一个数据项起始位置.
inline uint32_t NextEntryOffset() const {
return (value_.data() + value_.size()) - data_;
}
// 返回索引值为 index 的 restart 在 block 中的起始偏移量
uint32_t GetRestartPoint(uint32_t index) {
assert(index < num_restarts_);
return DecodeFixed32(data_ + restarts_ + index * sizeof(uint32_t));
}
// 将迭代器移动到索引值为 index 的 restart 对应的偏移量位置.
// 注意, 此方法只调整了 current_ 对应的 value_, 此时两者不再保持一致;
// current_ 与 key_ 仍然保持一致性.
void SeekToRestartPoint(uint32_t index) {
key_.clear();
restart_index_ = index;
// current_ 和 key_ 指向后续会被 ParseNextKey() 校正.
// ParseNextKey() 从 value_ 末尾开始, 所以这里需要设置好, 为何从 value_
// 末尾开始呢? 根据 Block 布局我们可以知道, value 位于每个数据项最后,
// 所以 value 之后第一个字节即为下一个数据项起始位置.
uint32_t offset = GetRestartPoint(index);
// 将 value 数据起始地址设置为 offset 对应的 restart 起始位置,
// value_ 这么设置是为了方便 ParseNextKey().
value_ = Slice(data_ + offset, 0);
}
public:
Iter(const Comparator* comparator,
const char* data,
uint32_t restarts,
uint32_t num_restarts)
: comparator_(comparator),
data_(data),
restarts_(restarts),
num_restarts_(num_restarts),
current_(restarts_),
restart_index_(num_restarts_) {
assert(num_restarts_ > 0);
}
virtual bool Valid() const { return current_ < restarts_; }
virtual Status status() const { return status_; }
virtual Slice key() const {
assert(Valid());
return key_;
}
virtual Slice value() const {
assert(Valid());
return value_;
}
virtual void Next() {
// 向后移动前提是当前指向合法
assert(Valid());
ParseNextKey();
}
// 将 current 指向当前数据项前一个数据项.
// 如果 current 指向的已经是 block 第 0 个数据项, 则无须移动了;
virtual void Prev() {
// 向前移动前提是当前指向合法
assert(Valid());
// 倒着扫描, 直到 current_ 之前的一个 restart point.
// current_ 大于等于所处 restart 段起始地址, 下面要做的
// 是寻找 current_ 之前的一个 restart point.
// 把 current_ 当前取值作为原点.
const uint32_t original = current_;
// 下面循环干一件事, 定位 current_ 前一个数据项, 具体分两种情况:
// - 如果 current_ 大于所处 restart 段起始地址, 不进行循环,
// 到下面去直接定位 current_ 前一个数据项即可.
// - 如果 current_ 等于所处 restart 段起始地址,
// - 如果当前 restart 不是 block 的首个 restart,
// 则 current_ 前一个数据项肯定位于前一个 restart 最后一个位置
// - 如果当前 restart 是 block 的首个 restart,
// 则 current_ 就是 block 首个数据项, 所以没有所谓前一个数据项了
// - 没有其它情况.
// 循环能够执行的唯一条件就是相等
while (GetRestartPoint(restart_index_) >= original) {
// 倒到开头的 restart point 了, 没法再向前倒了, 也就是没有 pre 了.
if (restart_index_ == 0) {
// current_ 置为同 restarts_,
// 即使得它位于 block 首个 restart 的首个数据项处.
current_ = restarts_;
// 将 restart_index_ 置为 restart point 个数,
// 这个索引是越界的.
restart_index_ = num_restarts_;
return;
}
// 倒车, 请注意.
restart_index_--;
}
// 粗粒度移动, 即先将 current_ 移动到指定 restart 分段
SeekToRestartPoint(restart_index_);
do {
// 细粒度移动, 将 current_ 移动到 original (current_ 移动之前的值)的前一个数据项
} while (ParseNextKey() && NextEntryOffset() < original);
}
// 寻找 block 中第一个 key 大于等于 target 的数据项.
// 先通过二分法在 restart 段级定位查找目标段, 存在
// key < target 且是最后一个 restart 段;
// 然后在目标段进行线性查找找到第一个 key 大约等于 target 的数据项.
// 如果存在则 current_ 指向该目标数据项; 否则 current_ 指向
// 一个非法数据项.
// 调用者需要检查返回结果以确认是否找到了.
virtual void Seek(const Slice& target) {
// 在 restart array 中进行二分查找, 找到最后一个
// 存在 key 小于 target 的 restart, 注意是小于,
// 这决定了后面二分查找时比较逻辑.
uint32_t left = 0;
uint32_t right = num_restarts_ - 1;
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr = DecodeEntry(data_ + region_offset,
data_ + restarts_,
&shared, &non_shared, &value_length);
// 注意, 在 block 中, 每个位于 restart 起始处的数据项的 key 肯定
// 是没有做过前缀压缩的, 所以 shared 肯定为 0.
// 同时要注意, 这是异常情况, 不属于循环不变式的成立的条件.
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
// 因为 block 中 key 都是递增排列的, 所以每个 restart
// 段位于 restart 首位置的那个 key 肯定是所在段最小的.
// 如果最后存在这样的 restart, 肯定是由 left 指向:
// - 因为 left 右移的条件是远小于 target
// - 因为 right 左移的条件是大于等于 target
if (Compare(mid_key, target) < 0) {
// Key at "mid" is smaller than "target". Therefore all
// blocks before "mid" are uninteresting.
left = mid;
} else {
// Key at "mid" is >= "target". Therefore all blocks at or
// after "mid" are uninteresting.
right = mid - 1;
}
}
// 即使初始 left == right 也会走到这
// 定位到目标 restart 段, 为下面线性查找打基础
SeekToRestartPoint(left);
// 定位到 left 指向的 restart 段以后, 挨个 key 进行比较,
// 寻找第一个大于等于 target 的 key
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
}
// 将迭代器移动到 block 第一个数据项
virtual void SeekToFirst() {
// 定位到第一个 restart 段
SeekToRestartPoint(0);
// 在之前基础上定位到第一个数据项
ParseNextKey();
}
// 将迭代器移动到 block 最后一个数据项
virtual void SeekToLast() {
// 定位到最后一个 restart 段
SeekToRestartPoint(num_restarts_ - 1);
// 在之前基础上定位到最后一个数据项
while (ParseNextKey() && NextEntryOffset() < restarts_) {
// Keep skipping
}
}
private:
// 如果出错, 则将各个成员置为非法值
void CorruptionError() {
current_ = restarts_;
restart_index_ = num_restarts_;
status_ = Status::Corruption("bad entry in block");
key_.clear();
value_.clear();
}
// 将 current_, key_, value_ 指向下一个数据项的
// 起始偏移量、key 部分、value 部分, 同时保持
// restart_index_ 与 current_ 新位置所处 restart 段一致.
bool ParseNextKey() {
// current_ 指向接下来的数据项
current_ = NextEntryOffset();
const char* p = data_ + current_;
// 数据部分之后紧接着就是 restart
const char* limit = data_ + restarts_;
if (p >= limit) {
// 数据部分到头了, 返回 false
current_ = restarts_;
restart_index_ = num_restarts_;
return false;
}
// 解码下个数据项
uint32_t shared, non_shared, value_length;
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
// key_ 保存的还是前一个数据项的 key,
// 而大小必然不小于接下来的数据项的 key 与其公共前缀部分大小
if (p == nullptr || key_.size() < shared) {
CorruptionError();
return false;
} else {
// 保留 key_ 与 key 公共前缀部分
key_.resize(shared);
// 将当前数据项 key 的非公共部分追加进来, 得到一个完整的 key
key_.append(p, non_shared);
// 当前数据项的 value 部分. 到此为止,
// current_、key_、value_ 都已指向同一个数据项.
value_ = Slice(p + non_shared, value_length);
// 因为 current_ 已经指向新的数据项, 所以它所处的 restart 段可能也递增了,
// 那就破坏了与 restart_index_ 的一致性, 所以需要调整.
// 下面循环干的事情, 就是要保持 restart_index_ 与 current_ 一致,
// 即让 restart_index_ 指向 current_ 所处 restart 在数组中的索引值.
// restart_index_ 如果指向最后一个 restart, 那么 current_
// 此时肯定也在最后一个 restart 段.
while (restart_index_ + 1 < num_restarts_ &&
GetRestartPoint(restart_index_ + 1) < current_) {
++restart_index_;
}
return true;
}
}
};
// 根据用户定制的 comparator 构造该 block 的一个迭代器
Iterator* Block::NewIterator(const Comparator* cmp) {
// block 尾部 4 字节为 restart 个数, 最少 4 字节
if (size_ < sizeof(uint32_t)) {
return NewErrorIterator(Status::Corruption("bad block contents"));
}
const uint32_t num_restarts = NumRestarts();
if (num_restarts == 0) {
return NewEmptyIterator();
} else {
// 将 block 作为数据源, 构造迭代器
return new Iter(cmp, data_, restart_offset_, num_restarts);
}
}从上面代码可以看出, 跟底层数据源相关的成员和方法都是 private 的, 迭代器接口方法实现都在 public 部分. 实现迭代器时依赖依赖两个重要的 private 方法, 一个是 SeekToRestartPoint() 一个是 ParseNextKey() 分别用于在迭代时实现先粗粒度后细粒度的目标定位.
2 双层迭代器设计
双层迭代器, 对应的类为 class leveldb::<unnamed>::TwoLevelIterator, 位于 table/two_level_iterator.cc 文件. 它的父类为 leveldb::Iterator, 所以表现出来的性质是一样的.
该类设计比较巧妙, 这主要是由 sstable 文件结构决定的. 具体地, 要想在 sstable 文件中找到某个 key/value 对, 肯定先要找到它所属的 data Block, 而要找到 data Block 就要先在 index block 找到其对应的 BlockHandle. 双层迭代器就是这个寻找过程的实现.
该类包含两个迭代器封装:
一个是 index_iter_, 它指向 index block 数据项. 针对每个 data block 都有一个对应的 entry 包含在 index block 中, entry 包含一个 key/value 对, 其中:
- key 为大于等于对应 data block 最后(也是最大的, 因为排序过了)一个 key 同时小于接下来的 data block 的第一个 key 的(比较拗口)字符串;
- value 是指向一个对应 data block 的 BlockHandle.
- 另一个是 data_iter_, 它指向 data block 包含的数据项. 至于这个 data block 是否与 index_iter_ 所指数据项对应 data block 一致, 那要看实际情况, 不过即使不一致也无碍.
示意图如下:
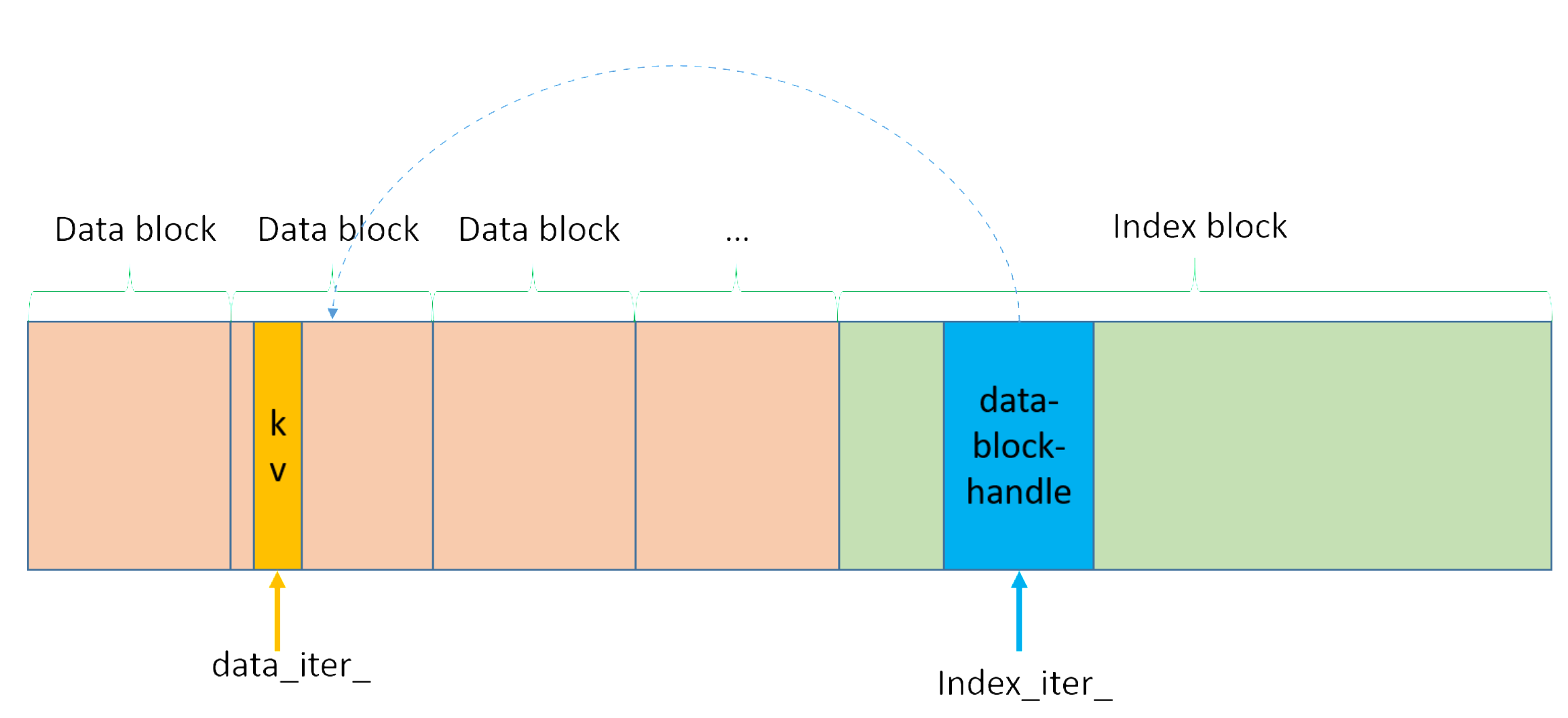
这两个迭代器, 可以把 index_iter 看作钟表的时针, 指向具体小时, 可以把 data_iter_ 看作更精细的分针, 指向当前小时的具体分钟. 两个指针一起配合精确定位到我们要查询的数据. 这么说其实就能大体上猜出来, 迭代器前后移动, 定位等等这些方法是如何实现的了, 简单说就是先移动 index_iter_ 再移动 data_iter_. 以 Seek() 方法举例来说:
// 根据 target 将 index_iter 和 data_iter 移动到对应位置
void TwoLevelIterator::Seek(const Slice& target) {
// 因为 index block 每个数据项的 key 是对应 data block 中最大的那个 key,
// 所以 index block 数据项也是有序的, 不过比较"宏观" .
// 先找到目标 data block
index_iter_.Seek(target);
// 根据 index_iter_ 设置 data_iter_
InitDataBlock();
// 然后在目标 data block 找到目标数据项
if (data_iter_.iter() != nullptr) data_iter_.Seek(target);
// data_iter_.iter() 为空则直接向前移动找到第一个不为空的
// data block 的第一个数据项.
SkipEmptyDataBlocksForward();
}可以看出, 双层迭代器设计具有分形的思想, 迭代器是由迭代器构成的.
其它方法实现原理类似, 不再赘述.
--End--