AI营销云数据体系架构设计
AI营销是负责讯飞自有媒体、外部媒体流量接入,进而变现的业务。随着业务的高速发展,数据需求越来越繁杂,数据驱动业务发展愿景的实现需要更加稳定、准确、高效、灵活的数据体系架构。得益于大数据生态开源社区的蓬勃发展,以及科大讯飞公司级大数据平台基础能力的演进,AI营销数据体系架构进行一系列升级。本文从数据收集、数据处理、数据服务、数据应用四个层面讲述数据体系架构设计的思路。
1 数据收集
平台接入的数据主要包括二大类:业务数据、广告流量数据,如图所示。
<center> </center>
</center>
1.1 业务数据
业务数据主要包括广告排期、广告订单、广告位置、客户数据、媒资数据,这些数据位于广告投放系统中其他业务系统或客户平台中。平台通过下面几种方式获取:
- 数据库数据同步
- 客户平台提供接口,通过接口拉取
- 客户提供Excel,通过邮箱自动拉取、解析
1.2 广告流量数据
广告流量数据主要包括ADX流量交易日志、DSP广告检索日志、曝光、点击、后续转化等数据。随着业务的发展,日均超过百亿级流量,峰值QPS 50万。Fluted是公司级大数据平台提供的数据接入工具,具有高可靠性、可水平扩展、高容错性、实时性,只需在业务机器上部署客户端即可自动采集业务日志。下游对接成熟的分布式消息队列Kafka,支持实时分析,同时将日志同步导入HDFS(根据Topic分拣到不同的数据存储路径)供离线分析。为了加快数据分析的效率,业务服务日志全部结构化。
2 数据处理
数据处理主要为两个方向(BI、推荐系统)提供支撑。BI方面,如何构建准确、一致、敏捷的数据处理系统以应对快速变化的业务,是数据处理系统的目标。我们按自顶向下(围绕目标的业务分析主题)和自底向上(各业务实体产生的业务过程)思路进行数据建模。
<center> </center>
</center>
2.1 自底向上
以一个完整的流量交易过程为例。主要涉及广告位、ADX、DSP、广告主/代理、排期、活动、订单、创意等实体。流量交易中,系统记录了详尽的实体交互过程,主要包括广告请求、竞价请求、参与竞价、竞得、订单排序、下发、曝光、点击等。为了能快速完成业务需求分析,同时具有较好的扩展性和查询性能,我们采用维度模型建模,构建公共数据层。
2.2 自顶向下
以媒体查量和流量预估为例。如下图,用户勾选想要的维度以及指标即可完成分析。ADS层主要基于业务需求构建基于场景的数据模型。
<center>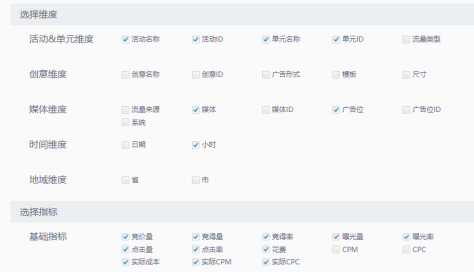 </center>
</center>
2.3 Session、实时聚合
Session即用户产生一个广告请求、曝光到点击的行为跟踪。曝光和点击事件的触发实质上是URL GET的过程,考虑业务安全,精简上报日志、节省用户流量,灵活性等方面,不适合在URL上添加参数(允许携带关键信息,如第三方监测需要)。
对于离线分析,通过请求信息补全曝光、点击信息很容易实现,但广告业务中大量的场景需要进行实时分析,如CTR预估,实时多维统计分析等。讯飞AI营销云目前采用成熟的Flink框架进行Session实时聚合,示意图如下所示。
<center>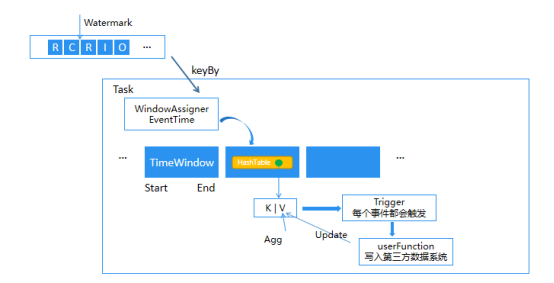 </center>
</center>
按Session实时聚合广告事件将带来如下几点好处:
- 数据完整性。减少http截断问题
- 节省上行流量。精简曝光和点击日志
- 灵活、敏捷。数据采集与服务端或客户端解耦
- 实时补全日志信息,可支持实时多维统计分析,在CTR预估方面也带来极大的提升
2.4 多维数据查询
多维数据查询解决方案是OLAP(On-Line Analytical Processing)系统,目前业界主要解决方案包括MPP架构、预计算、搜索引擎架构。
在实时分析场景下,Druid(MPP架构)能较好的满足需求(Schema向前兼容、TPS极高),不支持Cube剪枝,所有钻取查询均基于Base Cuboid的二次聚合(目前Kylin社区有Kylin On Druid的分支,用Druid代替HBase作为数据存储系统,系统在Druid上新增Cuboid维度,从而实现剪枝功能,但缺少实时摄入的功能)。在离线分析场景下,Kylin(预计算)更适合业务需求。
3 数据服务
数据经过生产、整合后,需要提供给产品、应用进行数据消费。数据服务可以使应用对底层数据存储透明,对外支持SQL化的REST或JDBC API。AI营销云数据服务主要提供数据查询服务,未来计划新增消息推送服务,让用户及时感知订阅的数据变化,提升工作效率。数据服务架构图如下所示。
<center> </center>
</center>
3.1 数据组织
数据服务按业务主题对数据进行组织,便于管理和查找。主题之下是根据业务需求构建的逻辑表,即根据物理表构建的逻辑视图。物理表就是数据源中的一张表,在元数据配置中存储的是表元信息。如下图所示,为方便用户查看,联合Config.ad_slot表和Log.media_traffic_query表,将id映射成name,从而构建了一张视图用户广告位流量查询(流量查询主题),如下图所示。可以看到这里数据查询的性能和灵活度取决于数据处理环节的数据建模工作。
<center>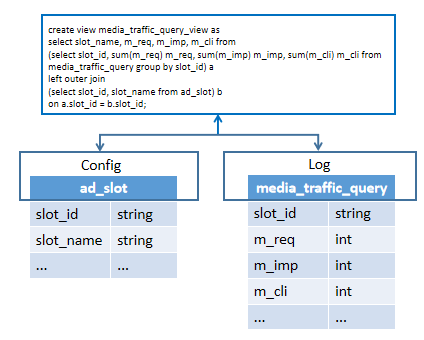 </center>
</center>
3.2 SQL处理引擎
我们对Presto的定位是支持异构数据源的SQL处理引擎,架构如下图所示。
<center>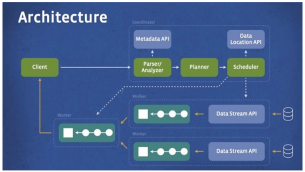 </center>
</center>
Presto Worker通过Data Stream API获取数据源数据,再进行初步聚合。如果底层对接的是Kylin,那么Data Stream将拷贝Kylin运行select * from table_name where XXX的数据,即将Base Cuboid拷贝到Presto Worker聚合,这种效率极其低下。为了利用Kylin系统的特性,我们对Presto进行业务定制,主要想法如下:
- 拦截用户SQL,提取catalog为kylin的完整语法树,并改为select *操作,如下所示:
- A, B, sum(C) C from kylin.a.b group by A, B
=>
select A, B, C from kylin.a.b
- 将提取的SQL传到与数据源交互层。具体实现类似JDBC Connector,重写QueryBuilder.buildSql。
Druid类似,一些细节问题上,如:udf的条件下推需要进行改造。下图数据源取自hbase和druid。
<center>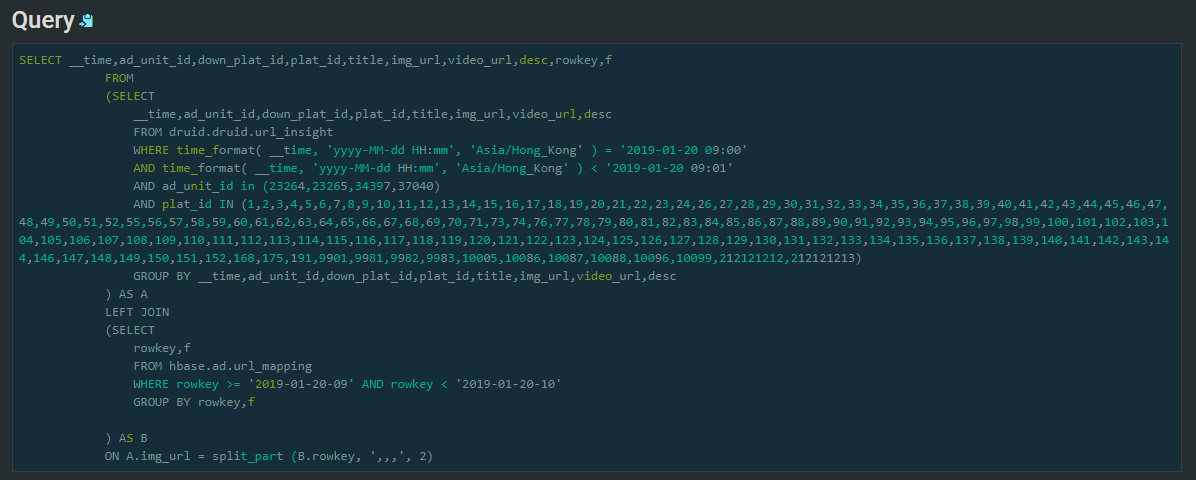 </center>
</center>
4 数据应用
4.1 自助BI
随着业务的发展,数据需求越来越多,基于人工编码完成需求的方式已经行不通。而一款简单、易用,能让用户自助分析的数据产品将带来效率的极大提升,并且丰富的可视化组件更易读懂数据背后的意义。
自助BI是公司级产品,数据源与可视化层解耦,我们只需对接数据接口即可(支持url参数控制权限)。自助BI支持标准模式和SQL模式,其中标准模式是拖拽的方式,用户只需拖拽关心的维度和指标(可配置基本的数据操作,如sum,count等);SQL模式非常灵活,可解决复杂的数据分析需求。
<center> </center>
</center>
结束语
本文从数据收集、数据处理、数据服务、数据应用介绍了AI营销云数据体系架构建设思路,限于篇幅原因未能逐个模块详尽介绍。未来着重在数据应用方面进行演进,如:结合自助BI,用户可以选中关键业务指标,后台将触发指标实时监控和智能诊断,高效赋能业务决策。
1 条回复关于AI营销云数据体系架构设计
很有深度的文章!!